Apple Claims Its ReALM Outperforms GPT-4 in Capabilities
Claude 3 Opus recently dethroned GPT 4 as the most advanced LLM. Meanwhile, researchers at Apple unveiled ReALM, shortly after the news that Google’s Gemini is powering the iPhone made headlines. The research paper, titled “ReALM: Reference Resolution As Language Modeling,” touts it as a cutting-edge AI system that promises to redefine how voice assistants understand and respond to user queries.
İçindekiler
The difference between ReALM and other systems lies in its seamless weaving of reference resolution into the fabric of language understanding. This is an innovative approach given the current design of large language model-based systems, and it helps enhance the model’s understanding of context while also establishing a new benchmark for interaction between AI and graphical user interfaces.
Based on the research outcomes, it is set to help LLM engineers and AI tool product managers achieve more intuitive and context-aware user interactions. ReALM also facilitates the integration of textual input with visual context, thereby expanding the potential for improving digital assistant skills in many applications.
ReALM’s Innovative Approach to NLP Reference Resolution
All NLP systems rely on “reference resolution,” a process to identify and link ambiguous yet contextual references such as pronouns or indirect descriptions, i.e., “they” or “that,” to the correct entities within a conversation or visual context to maintain coherent user interactions.
Traditional AI systems rely on rule-based methods or heuristics for reference resolution, which doesn’t yield the desired results when it comes to capturing the full complexity of natural language. As a result, visual context, such as on-screen entities, has been difficult to integrate into resolution using these methods. Voice assistants like Siri also fall prey to the same limitations that ReALM addresses by treating it as a language modeling problem.
ReALM harnesses LLMs to understand and resolve ambiguous references within the broader context of the conversation as opposed to using rules or heuristics. When visual context is involved, it rebuilds the device’s screen using textual representations and recording spatial connections between on-screen components.
Led by Joel Ruben Antony Moniz, the team of researchers states:
“To the best of our knowledge, this is the first work using a Large Language Model that aims to encode context from a screen.”
Result? ReALM-powered voice assistants can comprehend queries like “Tap the button on the top-right corner” and “Open the second article in the list,” which standard AI systems struggle with.
This makes ReALM’s reference resolution method more efficient and ideal for on-device processing as it can resolve references locally on the device, unlike cloud-based AI systems that need ongoing data transmission. This makes it a better fit for Siri due to improved privacy, latency, and offline functioning.
Click here for a list of the five best ChatGPT extensions.
Dataset Collection and Evaluation
The Apple research team curated a diverse dataset encompassing conversational, on-screen, and synthetic data to thoroughly assess ReALM’s ability to navigate the complexities of real-world user interactions compared to its alternatives. In order to do so, the team curated a diverse dataset encompassing conversational, on-screen, and synthetic data.
The conversational data was generated by showing crowd workers pictures containing synthetic lists and asking them to submit clear queries that relate to specific elements inside those lists. The on-screen dataset was subjected to a two-phase annotation process that ensured that the model could handle the complexity of real-world web pages. This process included classifying the visible objects, producing queries, and establishing connections between the queries and the entities they refer to.
Impressive Performance Results
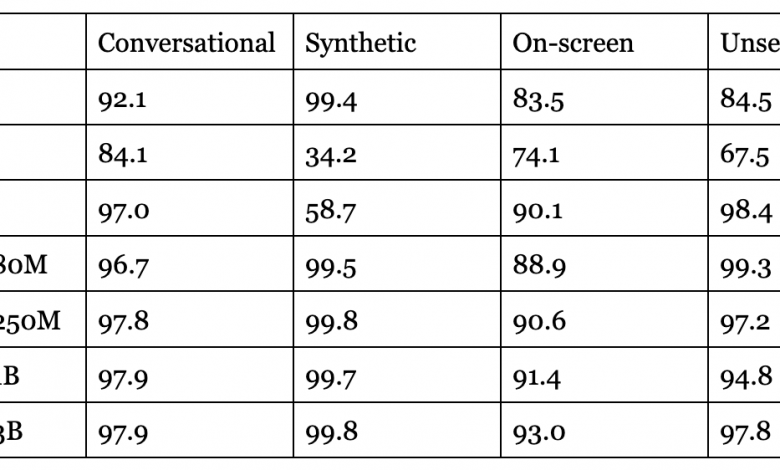
The evaluation results showcase the remarkable performance of ReALM across all datasets. Compared to MARRS, a previous state-of-the-art reference resolution system, ReALM achieves significant improvements in accuracy. Notably, even the smallest ReALM model obtains absolute gains of over 5% on the challenging on-screen dataset, demonstrating its ability to effectively understand and resolve references in complex visual contexts.
To further assess ReALM’s capabilities, the researchers benchmarked it against OpenAI’s GPT-3.5 and GPT-4 models. Impressively, ReALM’s smallest model performs on par with GPT-4 despite having orders of magnitude fewer parameters. As the model size increases, ReALM’s performance continues to improve, with the larger models substantially outperforming GPT-4 on the evaluated datasets.
The table below represents a summary of the performance results, highlighting ReALM’s superiority over existing approaches and its competitiveness with state-of-the-art language models.
The Key to Success: Optimal Screen Encoding
As evident, ReALM’s optimized screen encoding approach is a critical factor contributing to its impressive performance. This also adds to the fact researchers explored several strategies before arriving at the final algorithm, which proved to be the most effective.
One of the initial attempts involved clustering screen elements and including all other elements in each entity’s context. However, this led to prompt lengths expanding rapidly as the number of on-screen entities increased, rendering it quite impractical for real-world applications.
Another approach involved tagging entities in the textual screen parse but providing them separately from the main context. While this method appears promising, the researchers found that directly injecting the tags into the parse itself yielded the best results.
The final “injected on-screen encoding” approach, as described in detail in the paper, works by sorting the centers of screen elements from top to bottom and then from left to right. Elements within a specified vertical margin are grouped onto the same “line” in the textual representation, and elements on the same line are separated by tabs. This clever encoding scheme allows ReALM to approximate the 2D screen layout in a 1D textual format, enabling the model to effectively understand the spatial relationships between entities.
Ablation experiments conducted by the researchers confirmed the superiority of this optimized encoding approach, as shown in the figure below:

Handling Complex Use Cases
The paper provides several qualitative examples that showcase ReALM’s ability to handle complex use cases requiring various forms of reasoning, including semantic understanding, summarization, world knowledge, and commonsense reasoning.
In an interesting example shared by the team, ReALM correctly resolves the query “Call the evening number” to the phone number listed under “5 PM – 9 PM” when fed a screen showing both morning and evening contact information. Despite sounding like a logical outcome, this is an impressive display of capabilities as ReALM successfully understood the meaning of “evening” and mapped it to the appropriate time range, which is yet to materialize for other AI systems.
Another input sample included a screen displaying tax deadlines, and the mode successfully identified the April filing date as the relevant deadline when asked to set a reminder for printing documents before the tax due date.
These qualitative examples reinforce observations made on ReALM’s versatility and potential to handle a wide range of real-world scenarios that require deep language understanding and reasoning capabilities.
Advantages Over End-to-End Approaches
While end-to-end approaches relying solely on massive LLMs have shown promising results in various language understanding tasks, the researchers highlight several advantages of ReALM’s architecture:
Running a full end-to-end model on-device for latency and privacy reasons would be infeasible with current models due to computational and memory constraints. By using a smaller, fine-tuned model specifically designed for reference resolution, ReALM avoids these issues and enables efficient on-device processing.
Moreover, ReALM’s modular architecture allows for seamless integration with existing entity detection and task completion components in conversational AI pipelines. In contrast, an end-to-end model would require substantial changes to the entire pipeline, making it more challenging to adopt in real-world systems.
Scalability to New Entity Types
One of the key strengths of ReALM is its scalability to new entity types. Unlike previous pipelined approaches like MARRS, which relied on manually defined type-specific logic, ReALM’s LLM-based approach can easily generalize to unseen domains.
The researchers demonstrate this advantage by evaluating ReALM on an unseen “alarm” entity type. Impressively, ReALM matches the zero-shot performance of GPT-4 in accurately resolving queries like “Switch off the one reminding me to pick up didi” to the relevant alarm entity. This showcases the model’s ability to leverage its language understanding capabilities to handle new entity types without requiring explicit training data.
The table below presents the performance comparison between ReALM and GPT-4 on the unseen “alarm” dataset, highlighting ReALM’s strong zero-shot generalization abilities:

Future Possibilities and Limitations
Although ReALM delivers substantial progress in important aspects like reference resolution for conversational AI, the research team noted a few limitations that are worth understanding.
One major drawback of the system, however, is that converting a 2D screen layout into a 1D textual representation results in the loss of intricate spatial details. The team proposed the use of more advanced encoding strategies, such as portraying the screen components in a grid-like manner, in order to maintain more accurate relative locations.
Another potential improvement for the future is to enhance ReALM’s capability to handle more intricate and diverse references, including those that include temporal or hierarchical associations between entities.
Despite these limitations, ReALM’s impressive performance and scalable design make it a very promising foundation for further study and development in the domain of conversational AI.
Concluding Thoughts
ReALM’s ability to bridge the gap between textual input and visual context will pave the way for more intuitive and context-aware user interfaces. LLM engineers and developers will be able to create AI systems that truly understand and respond to users’ intentions, even when dealing with complex on-screen elements.
From a purely technical standpoint, ReALM’s modular architecture and on-device processing capabilities are particularly valuable since they not only address user privacy and latency issues but also set a precedent for more scalable, efficient, integrated AI systems.
In layman’s terms, ReALM’s success in handling complex use cases and its ability to generalize to new entity types signals the fact that our understanding of what’s currently possible with conversational AI has been completely altered. It could accelerate the somewhat stagnant AI adoption rate across industries ranging from customer service and e-commerce to healthcare and education.
Click here to learn all about investing in artificial intelligence.